Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Subscribe to our daily and weekly newsletters for the latest updates and content from the industry’s leading AI site. learn more
The beginning of Chinese AI DeepSeekknown as the leading AI developers with open source technologies, just dropped another bombshell: a new open source LLM called DeepSeek-R1.
Based on recently introduced DeepSeek V3 a type of hybrid expert, DeepSeek-R1 is compatible with the functionality of o1, OpenAI’s Frontier reasoning LLM, across mathematics, coding and reasoning. The best part? It does this at a very reasonable price, which shows that it is 90-95% cheaper than the latter.
The release marks a huge leap forward in the open game. It shows that open models are closing in on the competition for Artificial General Intelligence (AGI). To demonstrate the skill of its work, DeepSeek also used R1 to produce six models of Llama and Qwen, taking their performance to new levels. In one instance, the soluble version of Qwen-1.5B beat the larger versions, GPT-4o and Claude 3.5 Sonnet, in a mathematical selection.
These types of distilled, along with the main R1They are open and available at Hugging Face under the MIT license.
Its goal is to develop Artificial General Intelligence (AGI), a level of AI that can perform human-like intelligence. Many groups are increasingly focusing on the development of critical thinking skills. OpenAI made a notable move in its portfolio o1 examplewhich uses a process of reasoning to solve a problem. Through RL (reinforcement learning, or reward-driven optimization), o1 learns to control his thinking and improve the strategies he uses – eventually learning to identify and correct his mistakes, or try new strategies when the current ones don’t work.
Now, continuing to work in this direction, DeepSeek has released the DeepSeek-R1, which uses a combination of RL and fine-tuning to handle complex tasks and integrates with the o1 system.
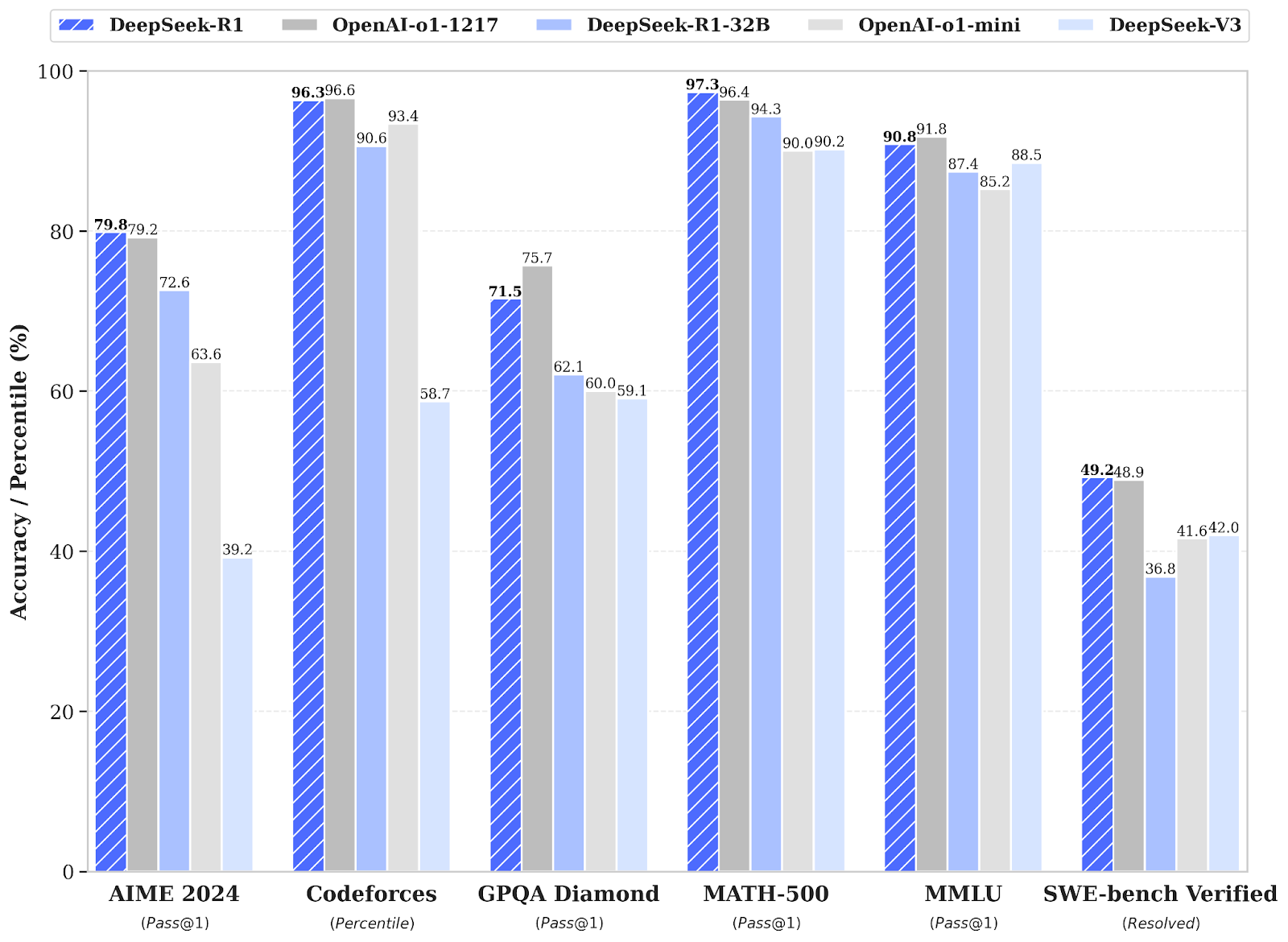
When tested, DeepSeek-R1 scored 79.8% on the AIME 2024 math test and 97.3% on the MATH-500. It also scored 2,029 on Codeforces – higher than 96.3% of human programmers. In contrast, the o1-1217 scored 79.2%, 96.4% and 96.6% respectively on these benchmarks.
It also showed strong recognition, with an accuracy of 90.8% on the MMLU, behind o1’s 91.8%.
The concept of DeepSeek-R1 shows the great success of the Chinese startup in the space dominated by US AI, especially since the entire project is open, including the way the company trained everything.
However, the task is not as straightforward as it sounds.
According to the research paper, DeepSeek-R1 was developed as an extended version of DeepSeek-R1-Zero – a successful method that was learned only from motivational studies.
https://twitter.com/DrJimFan/status/1881353126210687089
The company used DeepSeek-V3-base as a starting point, developing its thinking ability without using supervised data, mainly by focusing on its own adaptation through a trial and error method based on RL. Specially developed from the work, this skill proves that this model can solve the problems of thinking more by using a lot of time to try to analyze and revise his thoughts more deeply.
“During training, DeepSeek-R1-Zero naturally emerged with strong and interesting emotions,” the researchers wrote in the paper. “After thousands of RL steps, DeepSeek-R1-Zero shows high performance in benchmarks. For example, the pass@1 pass rate at AIME 2024 increases from 15.6% to 71.0%, and in the majority voting, the rating rises to 86.7%, compare the performance of OpenAI-o1-0912.
However, despite showing functionality, including practices such as meditation and alternative research, the first model showed some problems, including poor readability and language mixing. To this end, the company built on the work done on the R1-Zero, using a multi-level approach including supervised learning and reinforcement learning, and thus came up with an enhanced version of the R1.
“Specifically, we start by collecting thousands of cold source data to fine-tune the DeepSeek-V3-Base model,” the researchers explained. “Following this, we create a standard RL like DeepSeek-R1- Zero. When we approach integration in the RL process, we create new SFT data through sample rejection in the RL checker, combined with supervised data from DeepSeek-V3 in domains such as writing, QA facts, and self-identification, and retraining DeepSeek-V3 RL, considering the data from all the cases. After this, we found a checker called DeepSeek-R1, which fulfills the functionality of OpenAI-o1-1217.
In addition to performance comparable to OpenAI’s o1 in benchmarks, the new DeepSeek-R1 is significantly cheaper. In particular, where OpenAI o1 costs $ 15 per million entry tokens and $ 60 per million tokens, DeepSeek Reasoner, which was based on the R1 model, money $0.55 per million input and $2.19 per million output tokens.
https://twitter.com/EMostaque/status/1881310721746804810
This model can be tested as “DeepThink” on DeepSeek chat platformwhich is similar to ChatGPT. Interested users can access the sample weights and code repository through Hugging Face, under the MIT license, or they can go with the API to connect directly.



