Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Saturday, Three criminals CEO Oleksandr Tomchuk was informed that his company’s e-commerce website was down. It seemed like some kind of denial-of-service transmission.
He soon discovered that the culprit was a bot from OpenAI that was constantly trying to destroy his entire website.
“We have over 65,000 products, each with a website,” Tomchuk told TechCrunch. “Each page has at least three images.”
OpenAI was sending “thousands” of server requests trying to download all, hundreds of thousands of images, along with their detailed descriptions.
“OpenAI used 600 IPs to scrape the data, and we’re still analyzing last week’s logs, maybe more,” he said of the IP addresses the bot used to try to deface his site.
“Those browsers were breaking our website,” he said “it was a DDoS attack.”
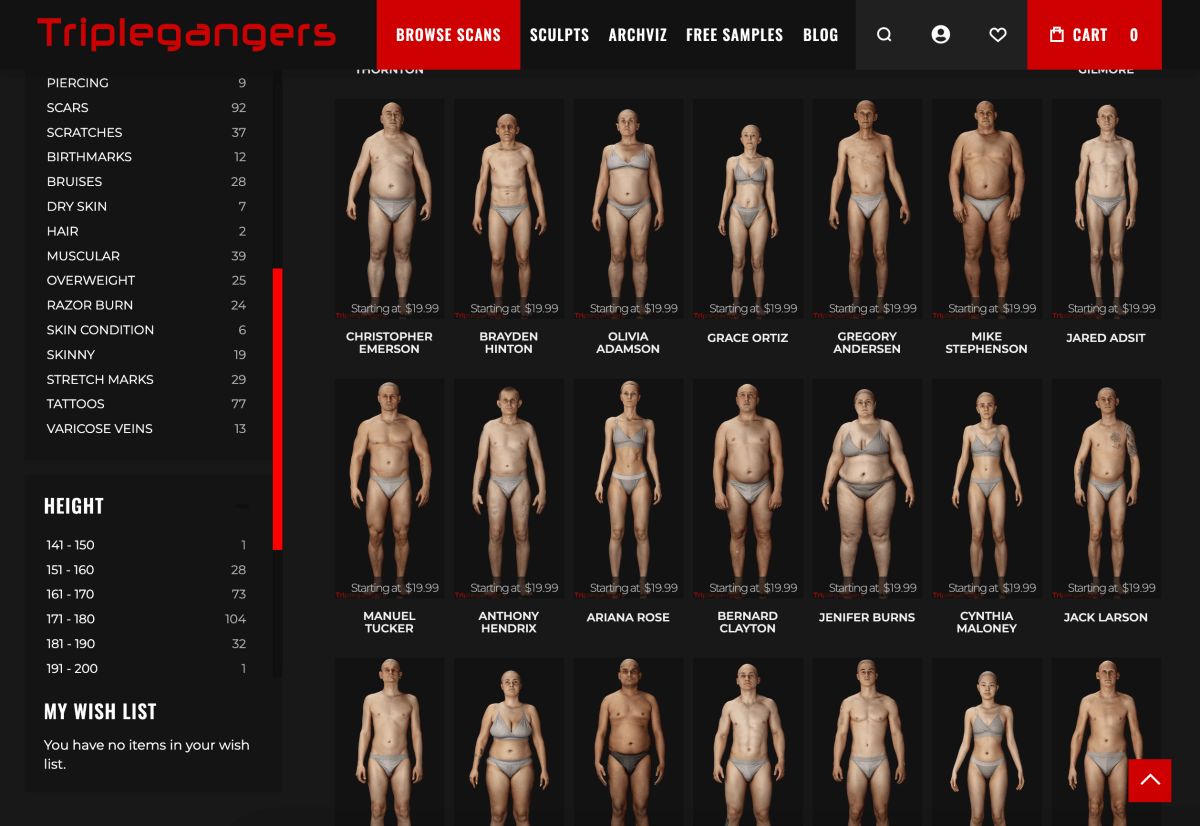
The Triplegangers website is his business. The seven-employee company has spent more than a decade amassing what it calls the largest database of “human figures” on the Internet, meaning 3D image files made from real human models.
It sells 3D object files, as well as images – everything from hands to hair, skin, and full bodies – to 3D artists, video game developers, anyone who needs to recreate a realistic human form.
Tomchuk’s group, originally from Ukraine and licensed to the US from Tampa, Florida, has job title page on his site that prevents bots from taking his photos without permission. But that alone did nothing. Websites should use a well-organized robot.txt file with tags that tell OpenAI’s bot, GPTBot, to leave the site alone. (OpenAI also has several bots, ChatGPT-User and OAI-SearchBot, which have their own tags, according to his web page on his reptiles.)
Robot.txt, also known as the Robots Exclusion Protocol, is designed to tell search engines what not to crawl when crawling the web. OpenAI states on its official website that it respects such files when configured with its crawler tags, although it also warns that it can take its bots up to 24 hours to detect a modified robot.txt file.
As Tomchuk noted, if a site doesn’t use robot.txt, OpenAI and others assume they can follow their content. It is not a way to enter.
To add insult to injury, not only was Triplegangers knocked offline by an OpenAI bot during the US service period, but Tomchuk expects to bill AWS for all the CPU and offloading from the bot.
Robot.txt is also not infallible. AI companies comply voluntarily. Another AI startup, Perplexity, was highlighted last summer by a Wired survey while other evidence shows that there was no mental disorder respect it.

By Wednesday, days after OpenAI’s bot returned, Triplegangers had a properly edited robot.txt file in place, and a Cloudflare account was set up to block its GPTBot and several other bots it had discovered, such as Barkrowler (SEO crawler) and Bytespider ( TokTok crawler). Tomchuk is also believed to have stopped crawlers from other AI companies. As of Thursday morning, the site had not been damaged, he said.
But Tomchuk has no clear way to determine what OpenAI has successfully captured or removed. Couldn’t find a way to contact OpenAI and ask. OpenAI did not respond to TechCrunch’s request for comment. And OpenAI has it so far it has failed to deliver its long-promised weaponas TechCrunch reported recently.
This is a very difficult issue for Triplegangers. “We’re in a business where privacy is a big issue, because we analyze real people,” he said. With regulations like Europe’s GDPR, “they don’t just take a picture of anyone online and use it.”
The Triplegangers website was also an interesting find for AI crawlers. Multi-billion dollar startups, like Scale AIwas created where people put images in depth to train AI. The Triplegangers page has photos labeled in detail: race, age, tattoos vs. scars, body types, etc.
Ironically, it was the greed of the OpenAI bot that alerted the Triplegangers as it was revealed. If it hadn’t been so slow, Tomchuk wouldn’t have known, he said.
“It’s dangerous because it seems that there is a way that these companies are using to crawl the data by saying “you can get out if you change your robot.txt with our tags,” says Tomchuk, but this puts the onus on the business owner to understand how to stop them.

They want other small businesses online to know that the only way to tell if an AI bot is taking copyrighted material is to do a quick check. He is not the only one who is threatened by them. Other website owners have also reported Business Insider how OpenAI bots hacked their sites and chased their AWS revenue.
The problem has gotten worse in 2024. A new study from the digital marketing company DoubleVerify found that AI crawlers and scrapers increased 86% in “unauthorized traffic” in 2024 – that is, traffic that does not come from a real user.
However, “many websites still don’t know that these robots have hijacked them,” warns Tomchuk. “Now we have to monitor the daily activities to see these bots.”
If you think about it, the whole model works like a mafia shakedown: AI bots will take what they want unless you have a defense.
“They should be asking for permission, not just deleting data,” says Tomchuk.
TechCrunch has a newsletter focused on AI! Log in here to get it in your inbox every Wednesday.


